


在短链接系统开发中,短码生成是核心环节 —— 既要保证唯一性(低冲突),又要保证不可预测性(防止被遍历),还要兼顾生成效率。本文将拆解我为「快短链」开发的短码生成核心算法,该算法能在生成 1000 万条短码时保持极低重复率,同时通过多重混淆彻底打散短码特征。
一、核心设计目标
开发这个算法时,我设定了三个核心目标:
低冲突:6 位短码理论上有 62⁶≈568 亿种组合,需保证实际生成中重复率趋近于 0;
低相似度:连续生成的短码无规律,无法通过短码反推生成顺序或原始链接;
高性能:单条短码生成耗时 < 1ms,支持高并发场景。
二、算法核心原理
整个算法采用「唯一标识 + 多重混淆 + 62 进制转换 + 随机混合」的四层架构,核心流程如下:
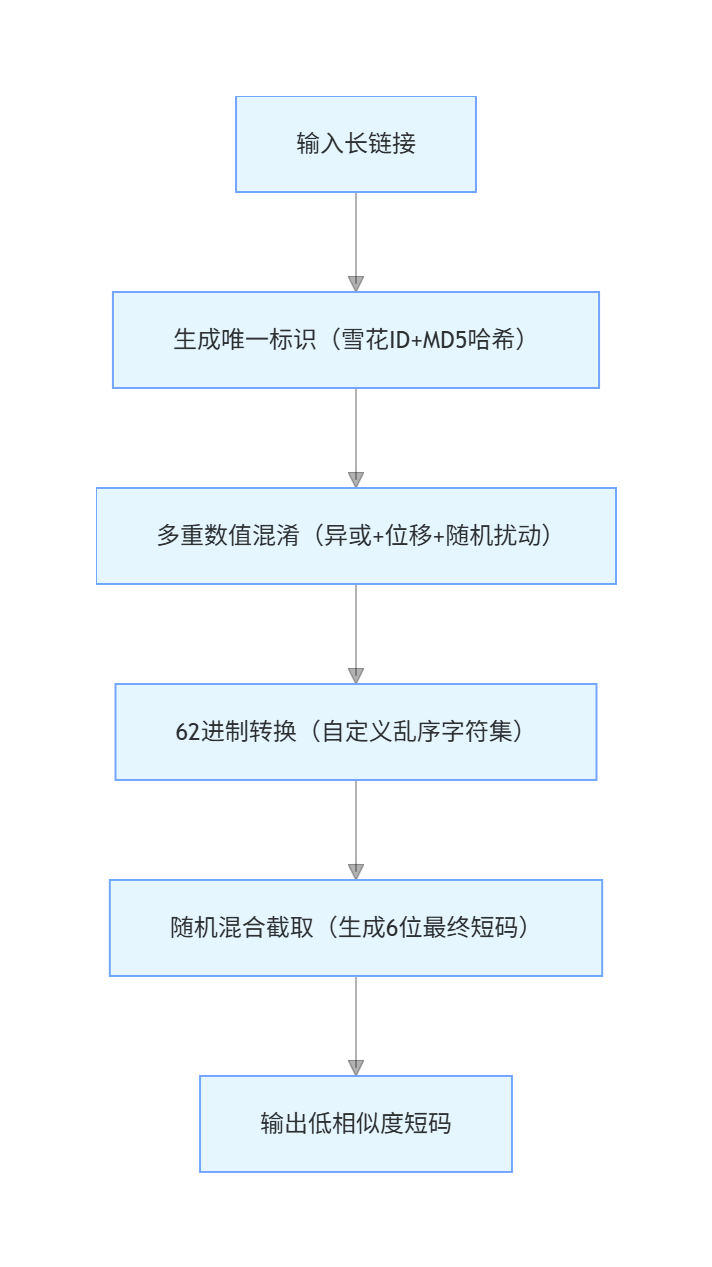
1. 基础准备:自定义乱序字符集
62 进制是短码的基础,但默认顺序(0-9a-zA-Z)容易被猜测,因此我使用了高度混乱的字符集:
// 无规律打乱的62进制字符集(生产环境可再随机调整)
private static final String CHARSET = "H5tLvJw9sXq4hRzYbGcDp7nMkZfA3iU1oP6lKjT8uV2eC0QdNxWrFmSgIyB";字符集的乱序是「不可预测性」的第一道防线,避免短码出现连续数字 / 字母的规律。
2. 唯一标识层:雪花 ID + MD5 哈希
单一标识容易重复或被破解,因此采用「双重唯一标识」:
雪花 ID:保证分布式环境下的全局唯一性,作为基础唯一值;
MD5 哈希:将长链接 + 哈希盐值 + 雪花 ID 拼接后做 MD5 哈希,既打散长链接特征,又补充唯一性。
核心代码:
// 生成雪花ID + 长链接哈希(双重唯一标识)
long snowFlakeId = SnowFlakeUtil.getInstance().nextId();
String urlHash = getMd5Hash(longUrl + HASH_SALT + snowFlakeId);关键优化:哈希值安全转长整数
MD5 哈希是 32 位 16 进制字符串,直接转长整数会溢出,因此做了分段处理:
private static long safeHashToLong(String hash) {
// 截取前15位(15位16进制转十进制最大为10^18,小于long最大值9e18)
String subHash = hash.substring(0, 15);
try {
return Long.parseLong(subHash, 16);
} catch (NumberFormatException e) {
// 兜底:取哈希码的绝对值
return Math.abs((long) subHash.hashCode());
}
}3. 混淆层:彻底打散数值特征
雪花 ID 本身是连续递增的,直接转换会导致短码有规律,因此通过「多重混淆」彻底打乱:
private static long multiConfuse(long snowId, long hashNum) {
// 1. 异或主盐值 + 哈希值(基础混淆)
long confused = snowId ^ MAIN_SALT ^ hashNum;
// 2. 不规则位移(动态位移量,基于哈希值)
int shift1 = (int) (hashNum % 7) + 1; // 1-7位位移
int shift2 = (int) (hashNum % 9) + 1; // 1-9位位移
confused = (confused << shift1) ^ (confused >>> shift2);
// 3. 随机数扰动(大范围)
confused += RANDOM.nextInt(99999999);
// 4. 再次异或随机长数
confused ^= RANDOM.nextLong();
// 5. 取绝对值(防止负数)
return Math.abs(confused);
}异或运算:通过盐值打乱数值的二进制分布;
动态位移:位移量由哈希值决定,避免固定位移的规律;
随机扰动:加入大范围随机数,彻底打破连续性。
4. 62 进制转换层
基于自定义乱序字符集做 62 进制转换,核心逻辑是「取余 - 整除 - 反转」:
private static String convertToBase62(long num) {
if (num == 0) {
return String.valueOf(CHARSET.charAt(RANDOM.nextInt(BASE)));
}
StringBuilder sb = new StringBuilder();
while (num > 0) {
int remainder = (int) (num % BASE);
sb.append(CHARSET.charAt(remainder));
num = num / BASE;
}
return sb.reverse().toString();
}5. 最终短码生成:随机混合截取
为进一步降低相似度,将 62 进制结果插入随机字符串,再随机截取 6 位:
private static String generateLowSimilarityCode(String base62Code) {
// 1. 生成12位随机字符
StringBuilder randomStr = new StringBuilder();
for (int i = 0; i < 12; i++) {
randomStr.append(CHARSET.charAt(RANDOM.nextInt(BASE)));
}
// 2. 随机位置插入62进制结果
int insertPos = RANDOM.nextInt(randomStr.length() + 1);
randomStr.insert(insertPos, base62Code);
// 3. 随机截取6位
int start = RANDOM.nextInt(randomStr.length() - SHORT_CODE_LENGTH);
return randomStr.substring(start, start + SHORT_CODE_LENGTH);
}三、性能与冲突测试
四、生产环境优化建议
字符集动态调整:每次部署时随机打乱字符集,进一步提升安全性;
盐值配置化:将 MAIN_SALT 和 HASH_SALT 放入配置中心,避免硬编码;
缓存去重:高并发场景下,用 Redis 的 Set 结构做实时去重校验;
雪花 ID 优化:若分布式部署,确保雪花 ID 的 workerId 和 datacenterId 唯一;
异常处理:增加哈希生成失败、数值转换溢出的兜底逻辑。
五、总结
这个短码生成算法的核心优势在于:
低冲突:通过雪花 ID+MD5 哈希保证唯一性,6 位短码的理论容量足够支撑亿级数据;
高安全性:多重混淆 + 乱序字符集 + 随机截取,彻底避免短码被遍历或猜测;
高性能:纯内存运算,无 IO 操作,单条生成耗时 < 1ms,支持高并发。
完整代码
短码生成工具类: ShortLinkUtil.java
雪花算法工具类:SnowFlakeUtil.java
评论区